If you don’t want your website’s content to be part of AI training data in the future, you can add a small file called robots.txt to your website’s root folder. (More on robots.txt)
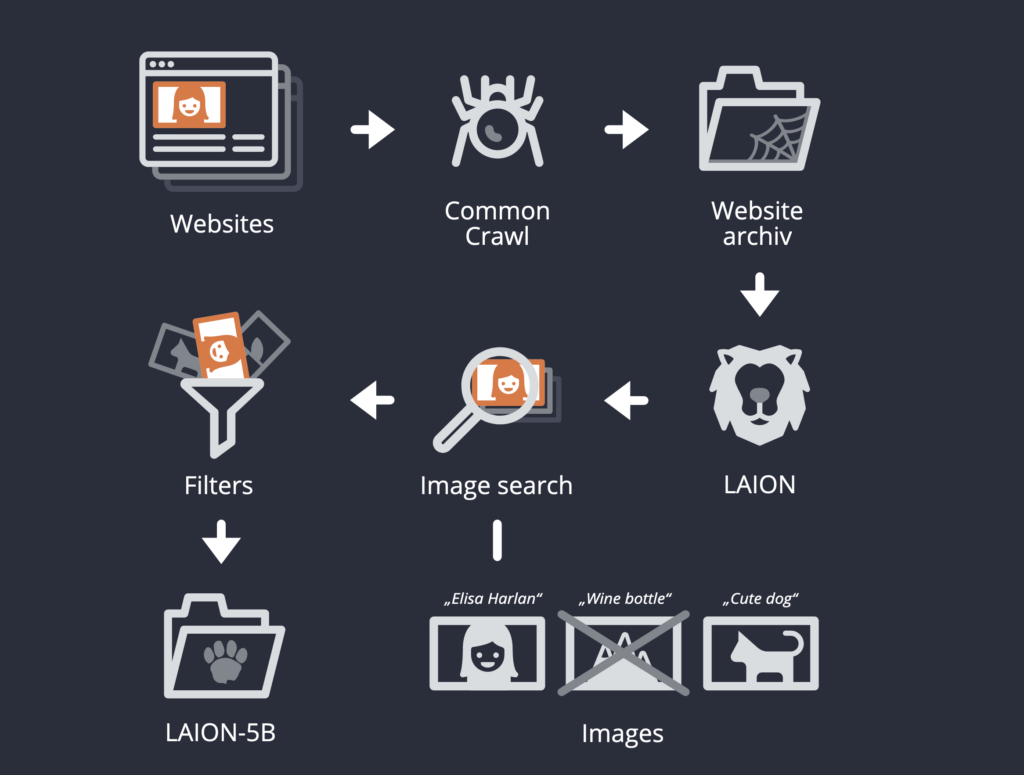
Finally, Open AI published information about its crawler a few days ago, see here. Many other organizations use Common Crawl dumps, e.g. LAION that gathered the training data for Stable Diffusion among others. Details on the Common Crawler.
So, what you need to do to prevent those crawlers from accessing your website: In the root folder of your website create a robot.txt file and add those four lines:
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /Now those two bots get content, of course there are loopholes and many more crawlers out there, e.g. for adding a website to Google.
OpenAI’s step forward to publish at least minimal information about the data harvesting process, is part of the bigger discussion around the vast amount of data needed to train AI models.
A few weeks ago, I published a bigger investigation on training data for generative AI:
We Are All Raw Material for AI
Training data for artificial intelligence include enormous amounts of images and text gathered from millions of websites. An analysis performed by German public broadcaster BR shows that it frequently contains sensitive and private data – usually without the knowledge of those concerned.
Read the story (in English)
Ein Kommentar