Building a first version of a digital collection using the Open Source software Omeka S is one thing. Inserting new data is a whole other beast. Why? At QueerSearch we want linked open data, especially for persons and organisation. So every time we import new data, we have to first look up, if an entity already exists. How to do that?
We already use OpenRefine to find people and organisations in Wikidata. We can now follow the same workflow but instead of checking Wikidata, we check our data in QueerSearch. Unfortunately, there is no Reconciliation API in Omeka S and we at QueerSearch are not the only ones missing it. But there is a workaround by creating a local reconciliation API based on a csv file: https://github.com/gitonthescene/csv-reconcile.
First, install the reconciliation service for OpenRefine based on a CSV file. It is a python library, so you can install it in multiple different ways, e.g. via pip, uv or poetry. Also, it has several plugins that offer different scoring methods. I added the fingerprint scorer, my first ever python plugin that published on pypi. Bascially, what it does: Detecting if firstname lastname is the same as lastname, firstname, a commen convention.
So, let’s get a bit more technical. First step, installing the software. I currently work with uv for managing virtual environments or installing python packages:
# create a new folder
mkdir reconcile-against-omeka-s
# move to folder
cd mkdir reconcile-against-omeka-s
# create a virtual environment
uv venv
# start virtual environment
source .venv/bin/activate
# install csv reconcile and fingerpring scorer
uv pip install csv-reconcile
uv pip install csv-reconcile-fingerprintNext step is to provide data you want to reconcile against as a csv file. As the docs say it needs to be a tsv file with two columns: some kind of id and a label.
For Queersearch this means: I want to get all persons and organisations we have in Omeka S. The starting point is a file exported by the Bulk Export module. Transform it in such a way that you get a distinct list with omeka_id and dcterms:title. This will be the reference file that we check against.
Very important: In order to match against the original data, copy the labels, because the reconciling process will change the values.
In R this code can look like this:
library(tidyverse)
export <- read_csv("data/csv-20250625-190809.csv")
persons_orgs <- export |>
filter(`o:resource_template` == "Personen und Körperschaften") |>
select(omeka_id = `o:id`, dcterms_title = `dcterms:title`) |>
mutate(dcterms_title_copy = dcterms_title)
write_tsv(persons_orgs, "data/persons-orgs.csv")Next, we need to initialise the reconciliation service by defining the reference file, the scorer and a config file, where we can link to our Omeka S instance. So when we click on a name during the reconciliation, we get a link to QueerSearch instead of Wikidata.
config.json:
MANIFEST = {
"view": {"url":"https://digital.katalog.queersearch.org/s/katalog/item/{{id}}"},
"name": "Queersearch Reconciliation Service"
}
SCOREOPTIONS={'stopwords':['e.V.', ' e.V.']}csv-reconcile init data/persons-orgs.csv omeka_id dcterms_title --scorer="fingerprint"So, now we can start the reconciliation service:
csv-reconcile serveThe service runs on http://127.0.0.1:5000/reconcile.
Then start Open Refine. Within the reconciliation service, click „Add standard service“ and add that URL:
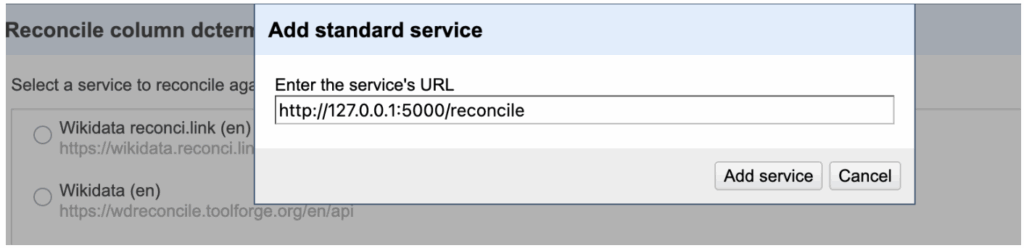
Now, we got

Then, I reconcile in two steps: First, against Omeka S instance.And then, for all that are not yet in Omeka S, against Wikidata.